(2019) Gotchas: Concurrent Execution and Maps in Java
Once upon a time, I was tasked with building a streaming Dataflow pipeline that looked something like this:
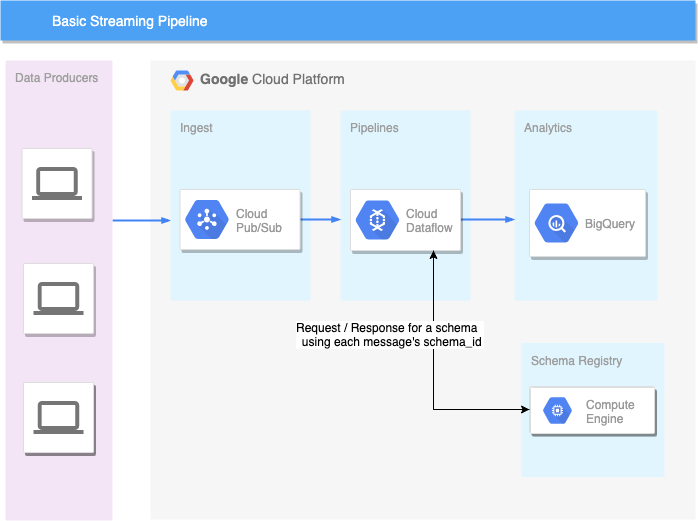
Data producers published messages containing a schema_id to Pub/Sub. Schemas would be resolved through a request to a Schema Registry (SR) to decode a message’s payload and write it to BigQuery.
Cache Me If You Can
The set of schema_ids / schemas is finite while the amount of messages we could receive is theoretically limitless. I decided to implement a cache at the worker level to minimize the number of calls to the SR. The idea was simple: query the SR any time a new schema_id was encountered and memoize the response. We could just use a HashMap to do this, right?
There’s an issue with this approach. This only works under a single-threaded execution mode. During multi-threaded execution keys are updated and read concurrently. In other words HashMap is not thread-safe out of the box. (For a primer on concurrency read this).
We could utilize the synchronized keyword to acquire the intrinsic lock associated with each Java object, granting exclusive access to the caller (thread). In a multi-threaded environment, the first thread would acquire the lock and subsequent threads would have their execution blocked until the first thread completed their work and released the lock. In essence, by using synchronized in this manner we’re forcing execution to occur in a single-threaded mode in order to gain thread-safety.
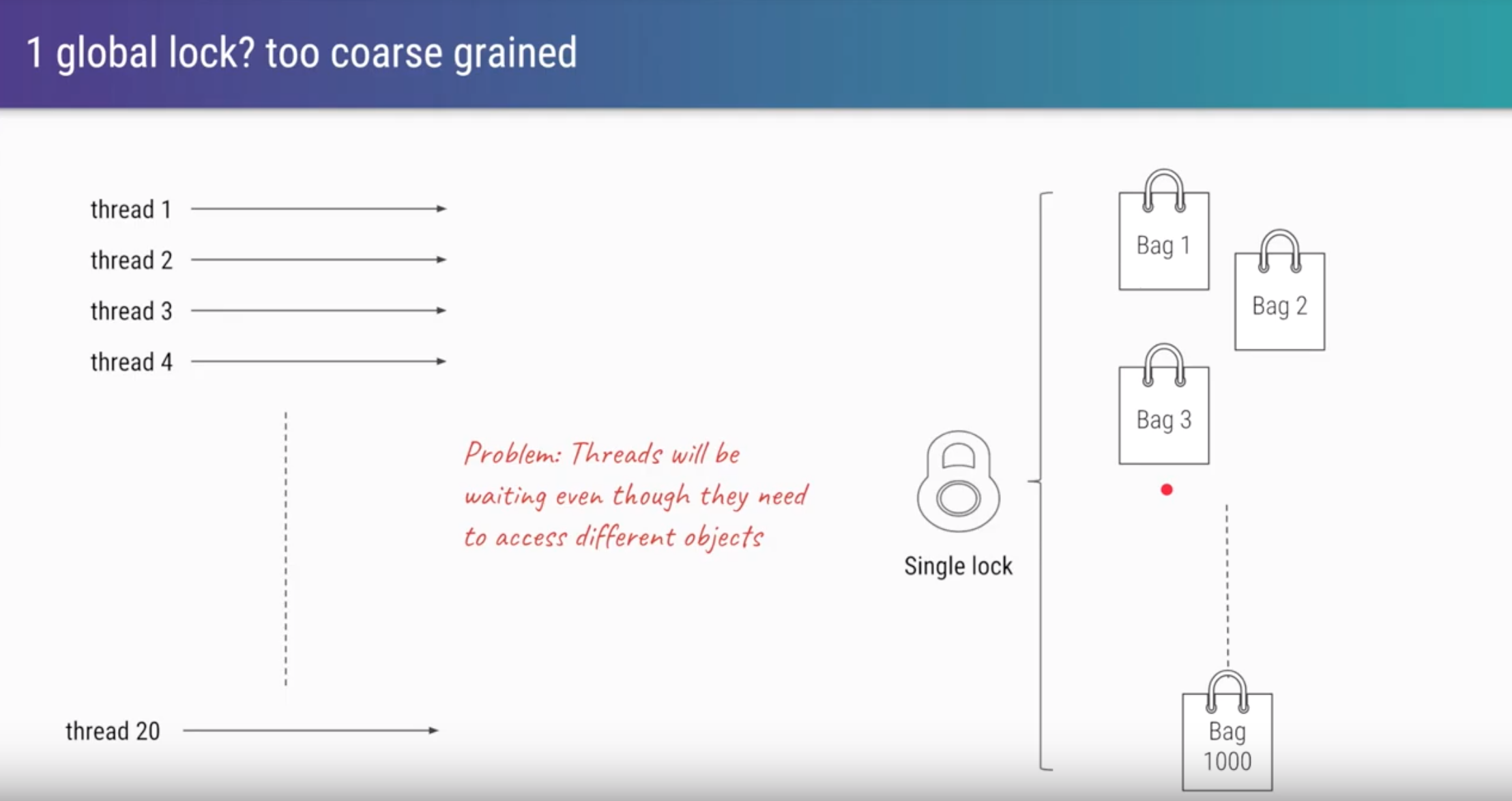
This adds undesirable latency overhead in the pipeline. Envision the following scenario:
- Dataflow’s autoscaler allocates a new worker with a new cache.
- The worker needs to process requests while simultaneously populating the cache from nothing, a cold-start.
- In the worst case scenario incoming messages would be blocked on cache warm up, with a potential one-time cost of the time it would take to resolve all schemas.
(It’s feasible to block incoming requests until the cache is adequately warmed, but let’s roll with this for now.)
While in this particular scenario, the latency from a cold-start wasn’t necessarily a show stopper I saw an opportunity to improve upon it.
How I learned to stop worrying and love java.util.concurrent
Lucky for us Java’s ConcurrentHashMap allows for multiple concurrent reads/updates by utilizing a technique known as lock-striping. The synchronized keyword locks the entire HashMap (and thus all keys), while lock-striping provides a more granular approach by using multiple locks. This makes it possible to modify multiple keys at once on a single map thus mitigating contention.
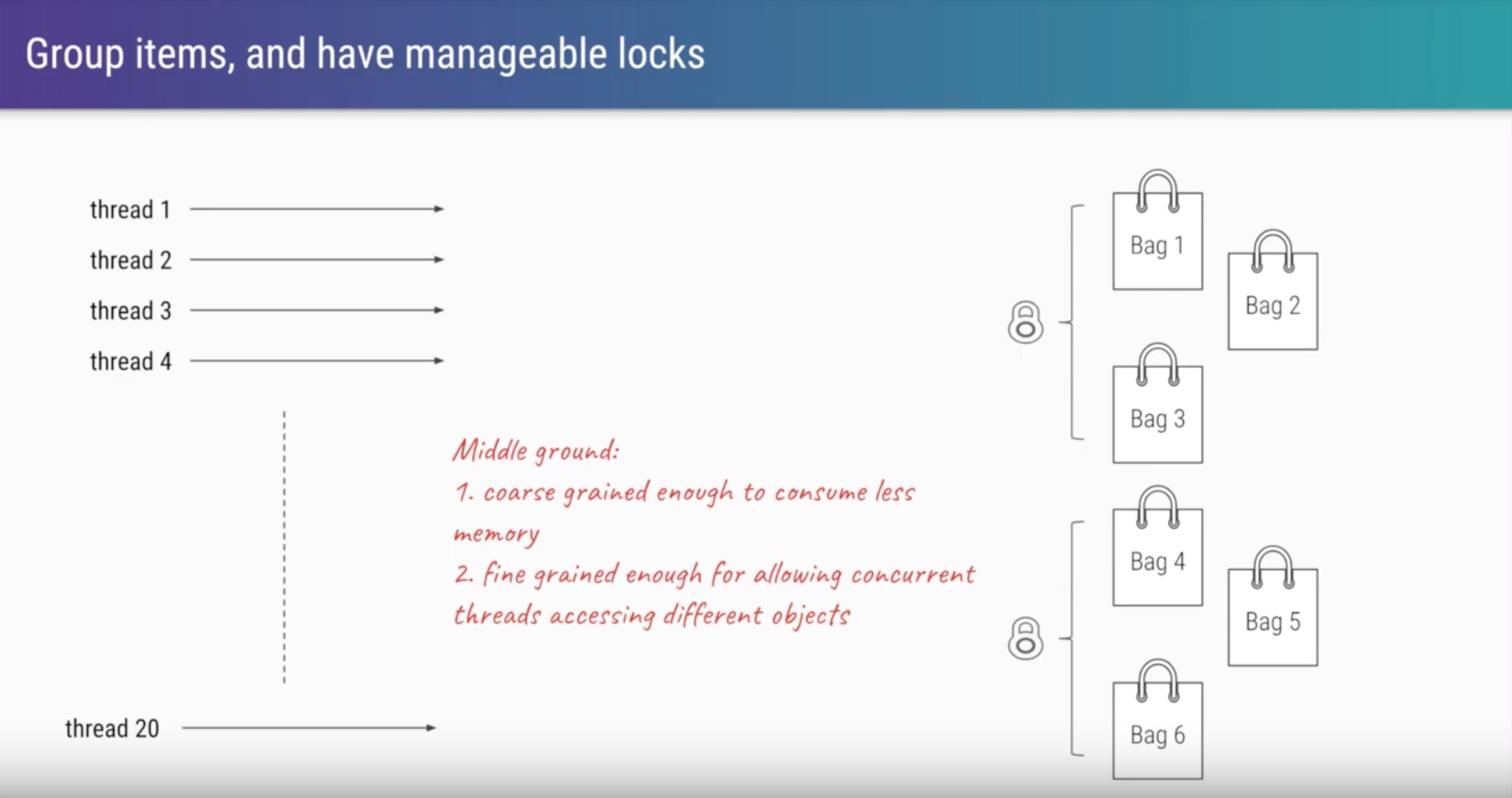
This is exactly what we’re looking for, thread-safety without significantly compromising performance.
Measure Twice, Cut Once
The Java Map interface has two methods for providing a default value when a key is missing: putIfAbsent and computeIfAbsent. The difference between these two is subtle, but significant to distinguish if you’re concerned about re-computation. In our case, re-computation means unnecessarily making multiple requests with the same schema_id.
Let’s take a look at ConcurrentHashMap’s documentation for a little more insight.
putIfAbsent documentation
If the specified key is not already associated with a value, associate it with the given value. This is equivalent to
if (!map.containsKey(key))
return map.put(key, value);
else
return map.get(key);
except that the action is performed atomically.
Atomicity is good, right? Atomicity typically means “all or nothing”, so either the key update happens or it doesn’t. That sounds like what we want, but what about computeIfAbsent?
computeIfAbsent documentation
If the specified key is not already associated with a value, attempts to compute its value using the given mapping function and enters it into this map unless null. The entire method invocation is performed atomically, so the function is applied at most once per key.
This is also an atomic operation, however there’s an additional detail: the function is applied at most once per key. Contrast this with the former’s documentation: the action is performed atomically.
What is the action is this scenario? Let’s look at a code sample.
public static void main(String[] args) throws InterruptedException {
Map<String, Integer> concurrentMap = new ConcurrentHashMap();
String key = "key";
ExecutorService exec = Executors.newFixedThreadPool(10);
ExecutorCompletionService compService = new ExecutorCompletionService(exec);
for (int i = 15; i > 0; i--) {
final int counter = i;
compService.submit(() -> {
if (args.length == 1 && args[0].equals("putTest")) {
concurrentMap.putIfAbsent(key, getValue(counter));
} else {
System.out.println("executing...");
concurrentMap.computeIfAbsent(key, getObjectIntegerFunction(counter));
}
return null;
});
}
exec.shutdown();
exec.awaitTermination(10L, TimeUnit.SECONDS);
System.out.println(concurrentMap.get(key));
}
private static Function<Object, Integer> getObjectIntegerFunction(int finalI) {
return (Object x) -> {
getValue(finalI);
return finalI;
};
}
private static Integer getValue(int finalI) {
System.out.println("starting " + finalI);
sleep(finalI);
System.out.println("completing " + finalI);
return finalI;
}
Full code here
In the above code we are:
- spawning an
Executorwith 10 threads - submitting 15
Callablesto theExecutorService - Inside each
Callableattempting to update a single key onConcurrentHashMapwithputIfAbsentorcomputeIfAbsent(depending on a runtime parameter) - The
Callablescontain print statements so we can observe execution behavior and how the threads interleave. - The last line of the output is the value associated with the key we’ve set.
Let’s take a look at putIfAbsent first.
starting 15
...
starting 7
starting 6
completing 6
starting 5
completing 7
starting 4
completing 8
starting 3
...
6
Truncated for brevity._
Here we can see calling putIfAbsent multiple times results in multiple evaluations of the getValue method per the starting X print statements. Another important observation is that the initial call is not the value populated in the map. The first value to be returned is what’s put in the map.
So in the output above:
- We’re counting backwards from 15 (
current_index) - Sleeping for an interval *
current_indexbefore returning thecurrent_index - We can see
getValue(15)was initiated, howevergetValue(6)completed first and is put into the map. - We can also observe that despite other computations completing (e.g.
completing 7), the initial designated value remains in the map.
This means any in-flight putIfAbsent calls to the same key will not update the map. This is what the Java docs mean by atomicity with putIfAbsent. The value portion of the putIfAbsent(key, value) call is evaluated each time regardless of whether or not the key exists in the map. This works fine if computing the value is relatively cheap, but if the computation involves calling an external service, all of a sudden you end up paying a non-trivial cost on each evaluation. What we actually want is lazy blocking evaluation. This is exactly what computeIfAbsent provides.
Let’s take a look at the computeIfAbsent output:
executing...
executing...
...
starting 15
executing...
completing 15
...
executing...
executing...
15
Truncating output again.
Here we can see executing… printed multiple times, which means multiple Callables containing with the computeIfAbsent call are being processed concurrently, however we only see starting and completing once. This confirms we’re only calling getObjectIntegerFunction once, and subsequent computeIfAbsent calls are blocked until the initial call has completed. Great success!
Closing Notes
This was a lot, and if you made it this far I commend you. While this approach worked for me, if your needs are slightly more complex you may want to look into using an external library such as Google’s Guava Cache, which behaves in a similar manner to ConcurrentHashMap. There are also a number of additional parameters/features which allow you to set time expiration policies, limit the cache size, add removal listeners, and more.
If you want to read more about concurrency in Java, I highly recommend Java Concurrency in Practice.
If there’s any lesson here, I implore you to read the documentation carefully. The additional effort will pay off dividends and save you time and headache down the road.
- TN